
DynamoDB のキャパシティユニット、テーブル構造、パーティション分割について図解でおさらい
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
コーヒーが好きな emi です。
DynamoDB の調査をする機会があったのですが、DynamoDB の仕組みについてすっかり忘れてしまっていたため、絵を描きながらおさらいしました。
ドキュメントはこちらのチートシートがよくまとまっていて便利です。
キャパシティユニット (Capacity Unit、CU)
DynamoDB テーブルでは書き込みと読み込みの性能を「キャパシティユニット (Capacity Unit、CU) 」という単位で換算します。
RCU と WCU
- 読み込みキャパシティユニット (Read Capacity Unit、RCU)
- 最大サイズが 4KB のアイテムについて
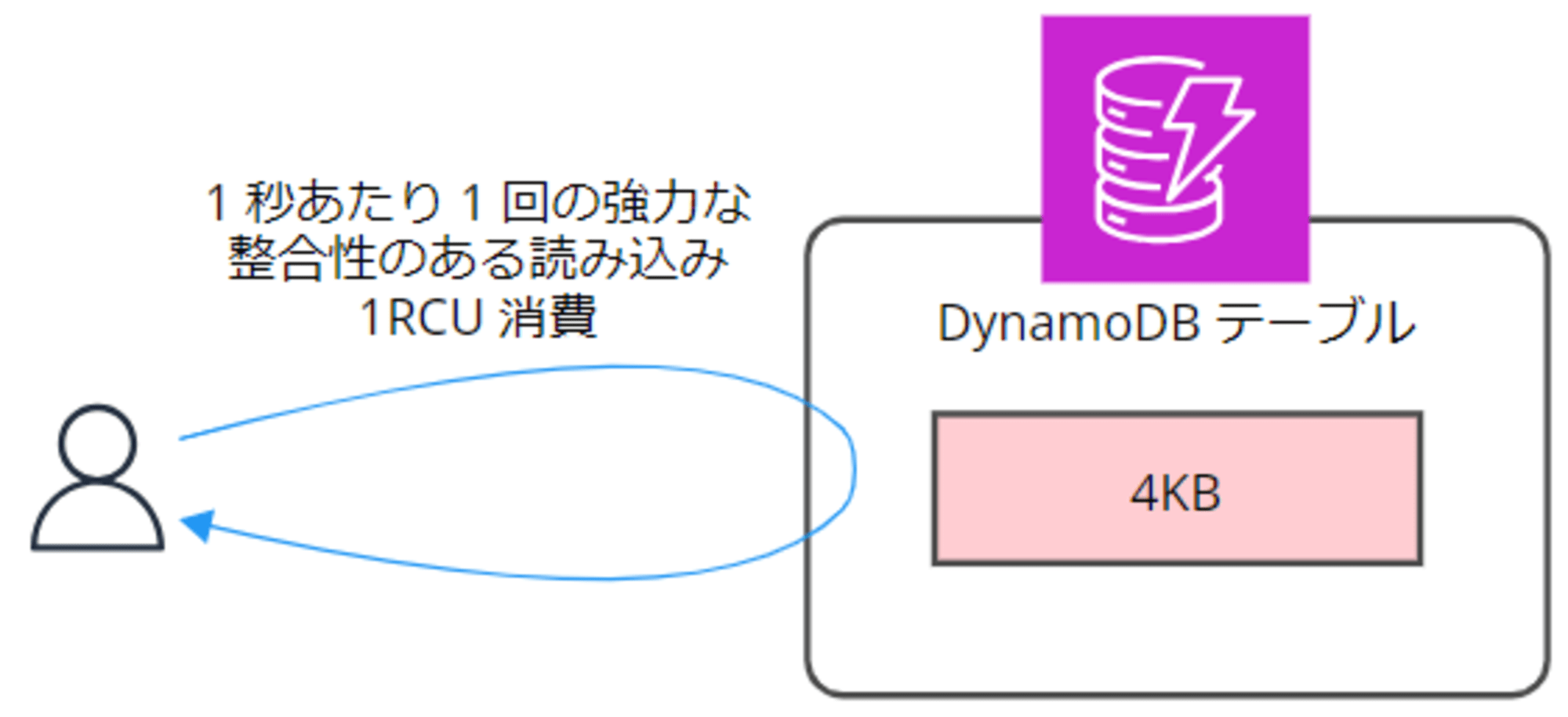
- 1 秒あたり 1 回の強力な整合性のある読み込み = 1RCU 消費
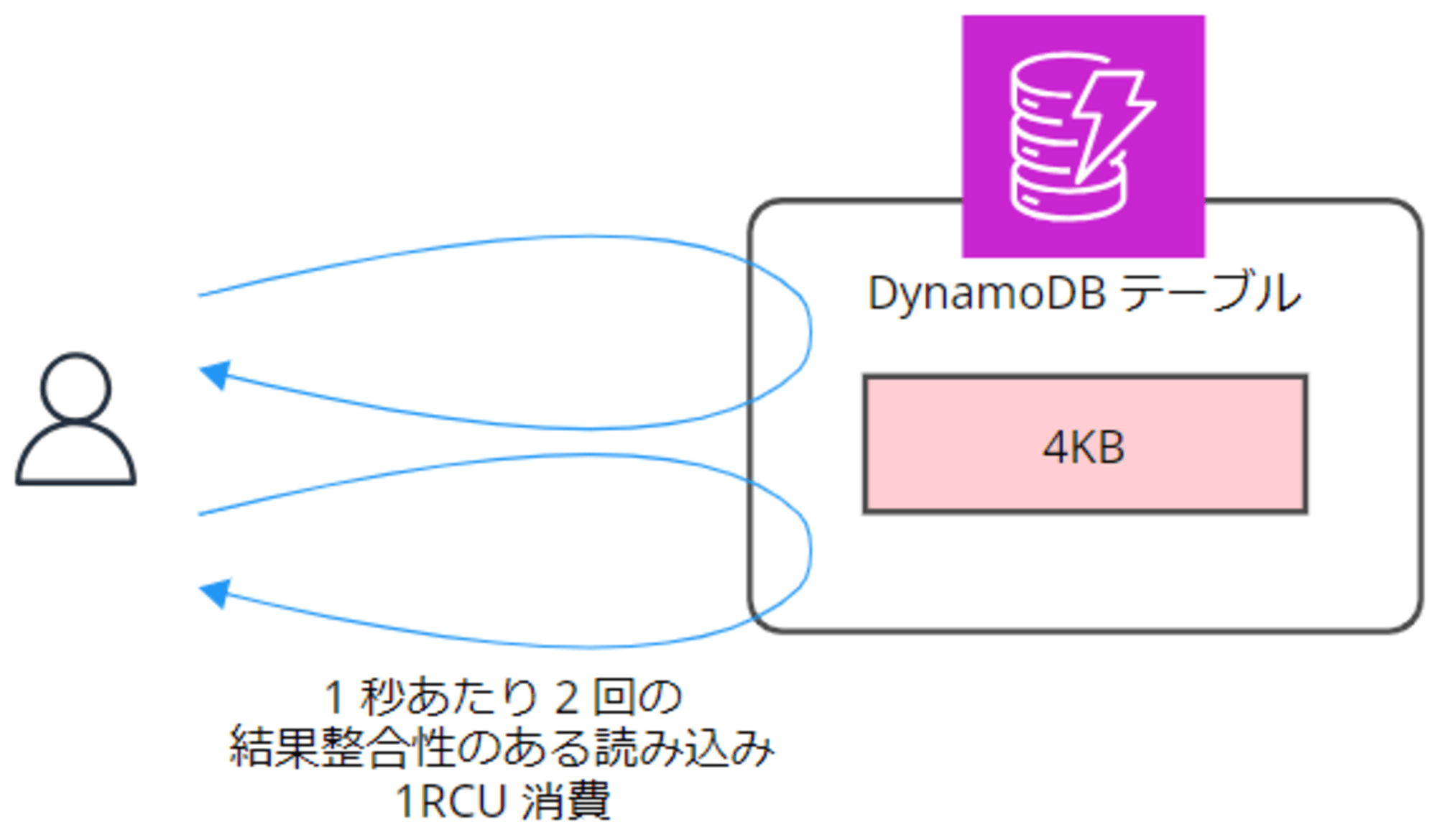
- 1 秒あたり 2 回の結果整合性のある読み込み = 1RCU 消費
- 例)
- 1 秒間に 16KB のアイテムを強力な整合性で 1 回読み込む場合、16KB ÷ 4KB = 4RCU 消費
- 1 秒間に 16KB のアイテムを結果整合性で 1 回読み込む場合、消費する RCU は強力な整合性の半分なので、2RCU 消費
- 最大サイズが 4KB のアイテムについて
▼強力な整合性のある読み込み
▼結果整合性のある読み込み
- 書き込みキャパシティユニット (Write Capacity Unit、WCU)
- 最大サイズが 1 KB の項目について、
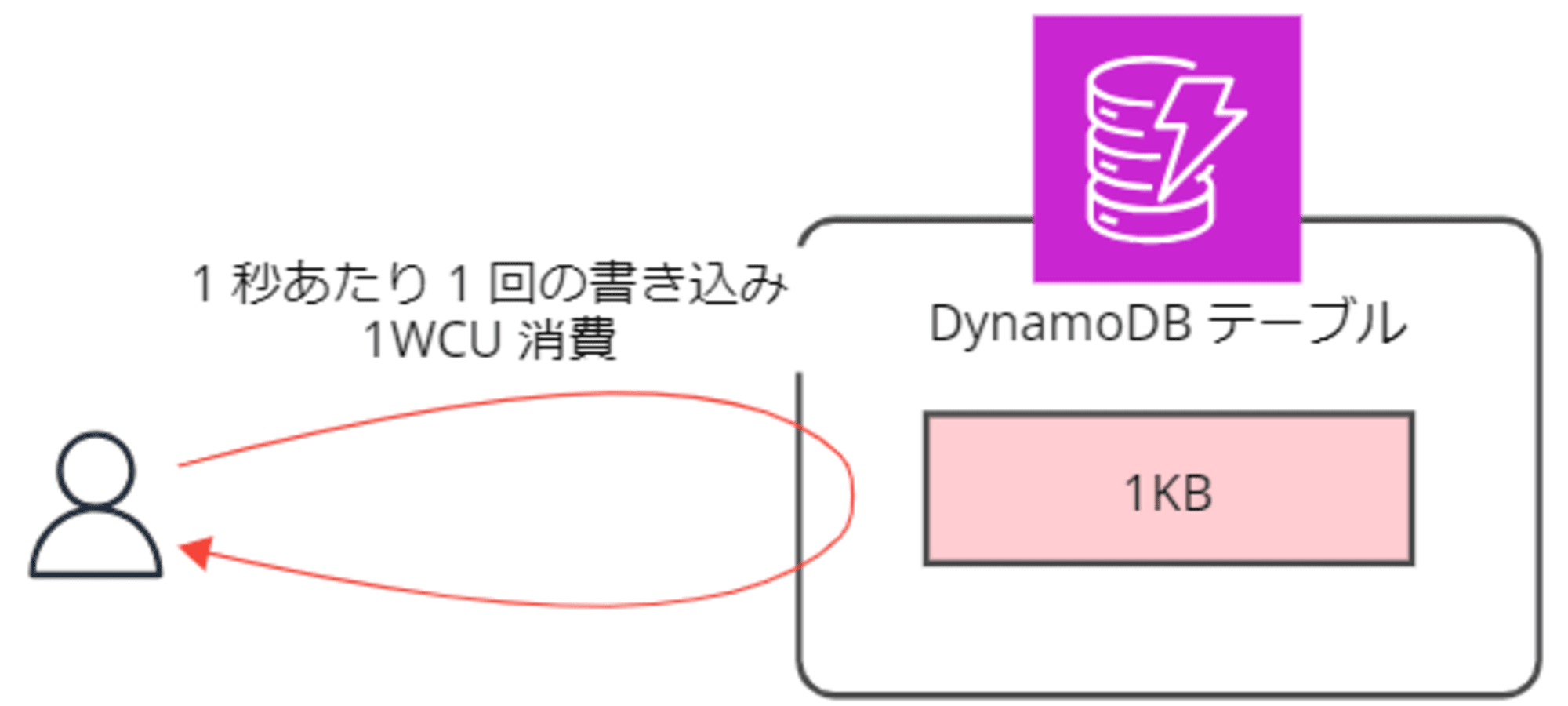
- 1 秒あたり 1 回の書き込み = 1WCU 消費
- 例)
- 1 秒間に 16KB のアイテムを 1 回書き込む場合、16WCU 消費
- 最大サイズが 1 KB の項目について、
▼書き込み
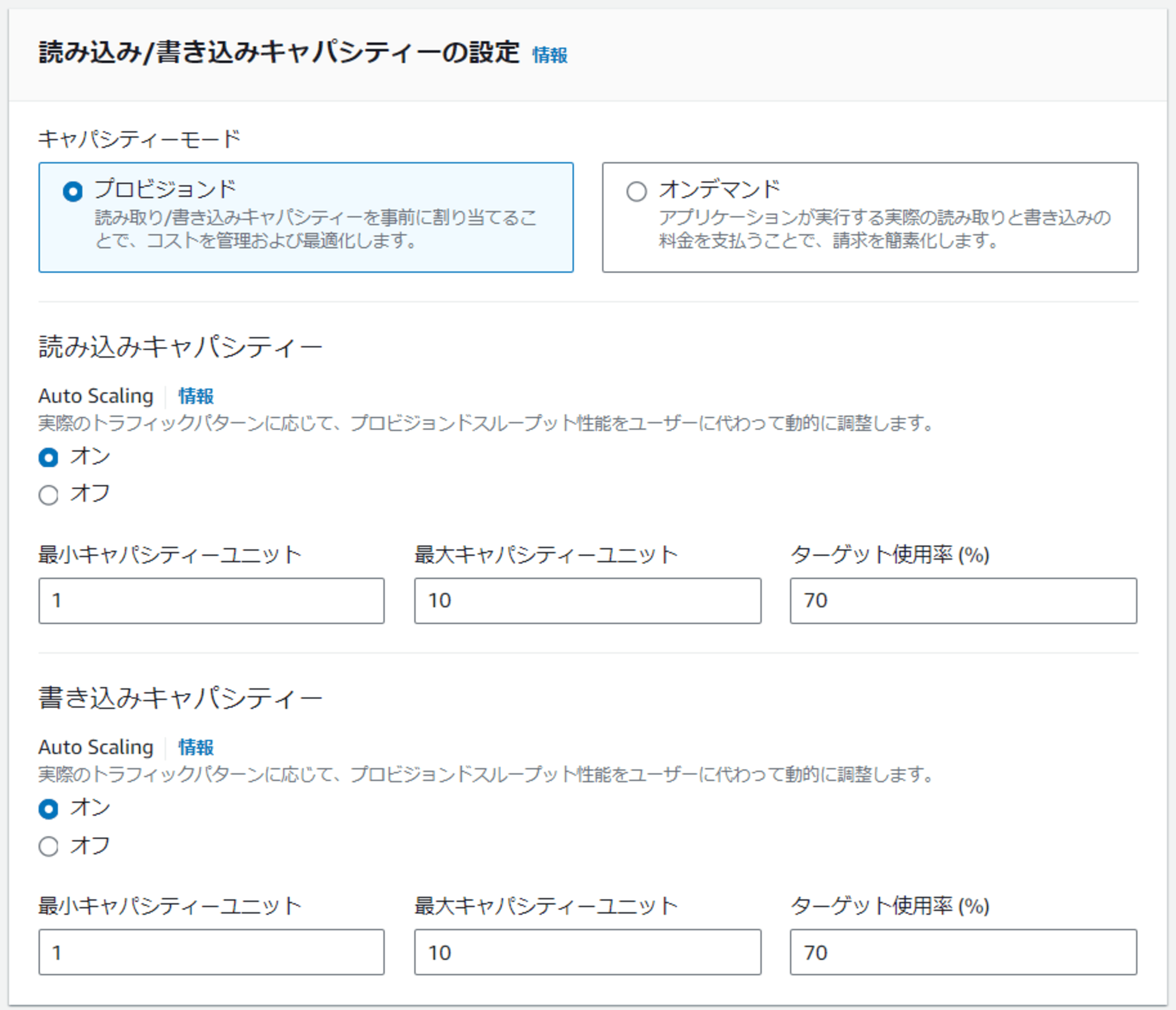
キャパシティモード
用途に合わせて以下 2 種類のキャパシティモードから設定できます。
- プロビジョンド (キャパシティ) モード
- DynamoDB のテーブルにあらかじめキャパシティユニットを割り当てておく
- 常にプロビジョニングした分の料金を支払う
- オンデマンド (キャパシティ) モード
- システムの書き込み・読み込みリクエストに応じて自動でキャパシティユニットを増減する
- 発生した読み込み、書き込みに応じて支払う
オンデマンドキャパシティモードの場合、「RCU」、「WCU」ではなく「読み込みリクエストユニット (Read Request Unit、RRU) 」「書き込みリクエストユニット (Write Request Unit、WRU) 」と呼びます。
DynamoDB の Auto Scaling
DynamoDB でも Auto Scaling が利用できますが、何を Auto Scaling してくれるのかと言うと、プロビジョンドキャパシティユニットを Auto Scaling してくれます。
「えっそれってオンデマンドモードじゃないの?」
みたいな気持ちになりますが、ちょっと違います。
オンデマンドモードはユーザーが介入することなく AWS 側で全自動でキャパシティユニットを調整します。ユーザーは最大キャパシティユニットを指定するのみです。
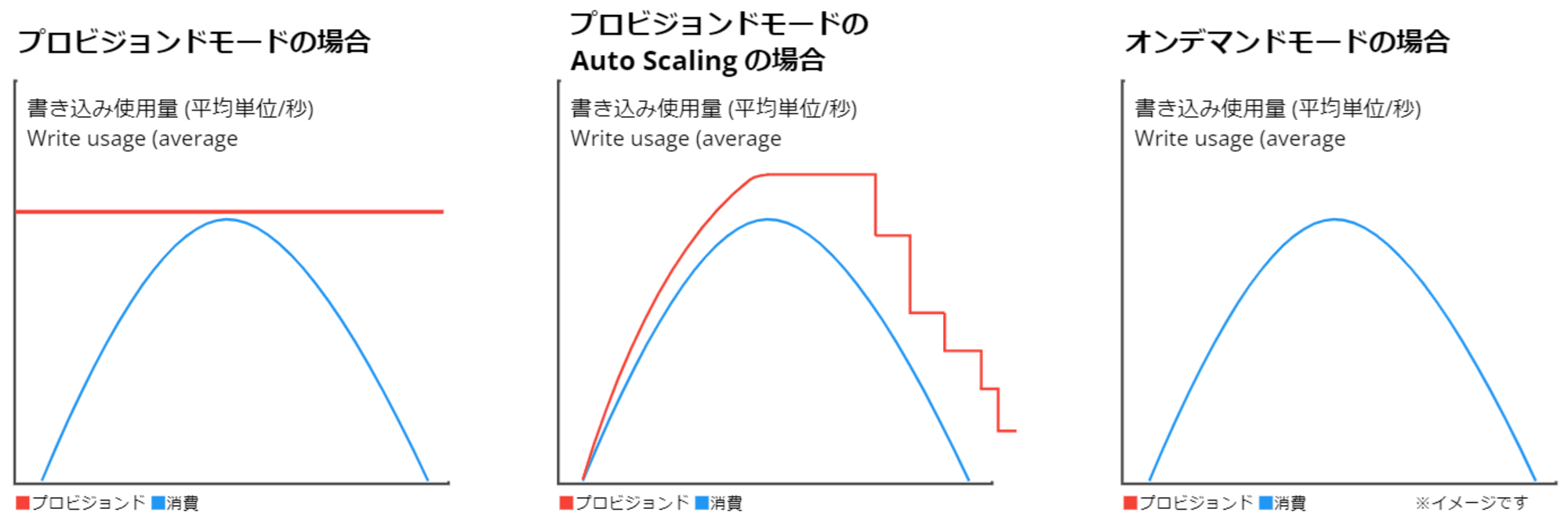
プロビジョンドモードの Auto Scaling では、ユーザーが「ターゲット使用率 (%)」を指定します。
消費されたキャパシティが、設定したターゲット使用率を 2 分間連続して超過すると、自動スケーリングがトリガーされます。
消費されたスループットのスパイク間隔が 1 分を超えると、自動スケーリングはトリガーされない場合があります。
DynamoDB は消費されたプロビジョンドスループットを 1 分間隔で CloudWatch に出力していますが、15 個の連続するデータポイントがターゲット使用率を下回ると、スケールダウンイベントが発生します。
Auto Scaling ターゲット使用率の値は 20% から 90% の間で設定できます。
グラフにすると以下のようなイメージです。
DynamoDB テーブルの仕組み
DynamoDB ではテーブルの中に「アイテム (項目) 」と呼ばれる形でデータが保存されます。この「アイテム」は、リレーショナルデータベース(RDB)で言うところの「レコード」です。
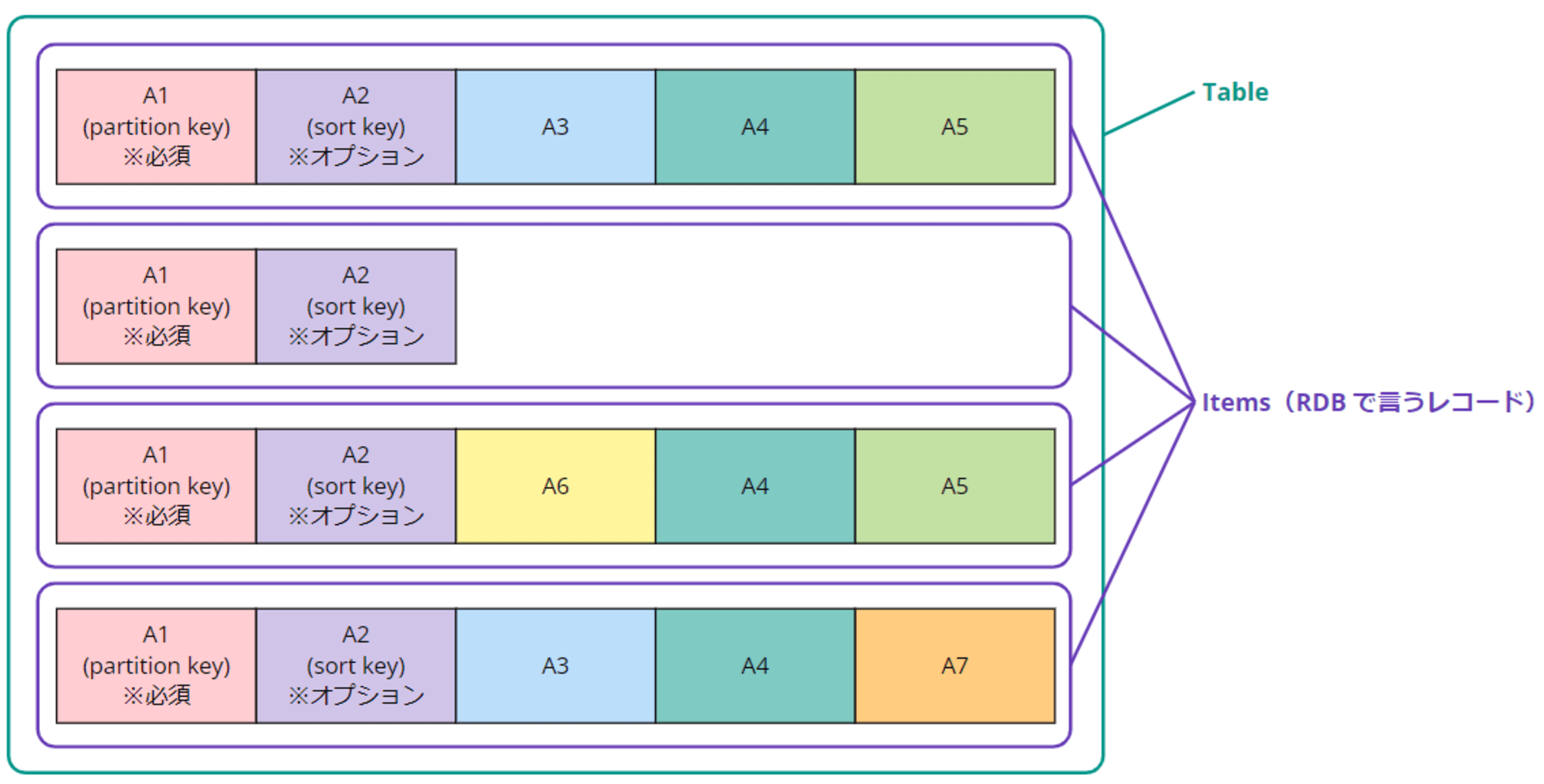
DynamoDB には以下のようなキーが存在します。
- プライマリキー
- パーティションキー(旧ハッシュキー)※必須
- ソートキー(旧レンジキー)※オプション
- セカンダリインデックス ※オプション
- ローカルセカンダリインデックス(LSI)
- グローバルセカンダリインデックス(GSI)
データを一意にするため、DynamoDB でテーブル作成時に プライマリキー を決定しておく必要があります。
- プライマリキー のパターン
- パーティションキーのみでプライマリキーとするパターン
- パーティションキーとソートキーのセットでプライマリキーとするパターン
パーティションキーはテーブル作成時に必須で、パーティションキーのみでアイテムが一意に特定できる場合はパーティションキーのみでプライマリキーにできます。
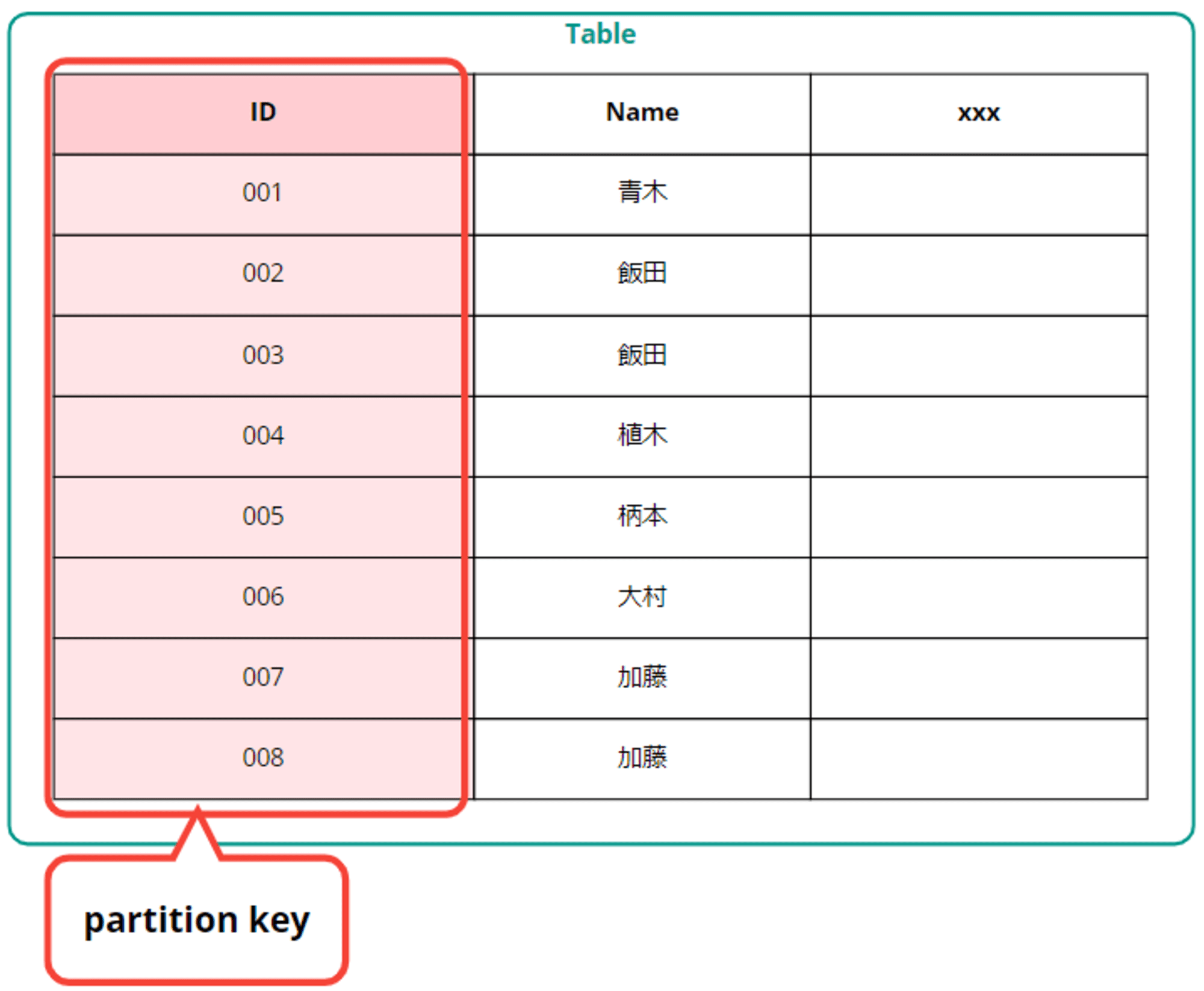
パーティションキーだけで一意に定まらない場合はソートキーもあわせて設定し、プライマリキーにすることができます。
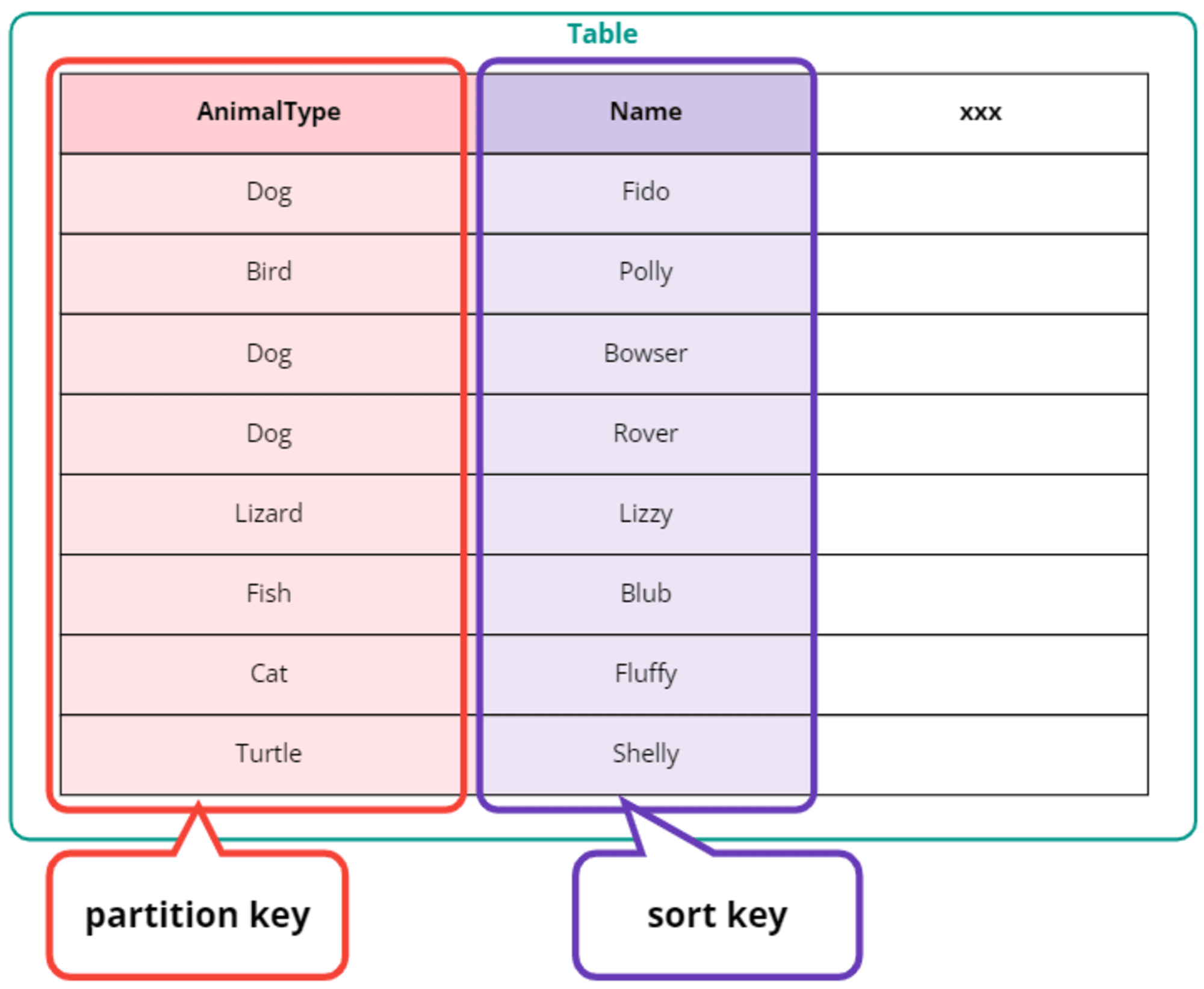
ソートキーによって各パーティション内でインデックスが生成され、範囲(レンジ)指定した検索ができます。このため昔はソートキーをレンジキーと呼んでいました。
テーブル名、パーティションキー、ソートキーはテーブル作成時にしか指定できず、テーブル作成後の変更はできません。
本記事ではセカンダリインデックスの説明は省きます。
パーティショニング(パーティション分割)
DynamoDB では大量データを高速処理するため、パーティショニングによる分散処理を行っています。「パーティション」と呼ばれる分割された小さな領域(ストレージ)に、アイテムを分散して格納します。
パーティションは SSD によってバックアップされ、AWS リージョン内の複数のアベイラビリティーゾーン間で自動的にレプリケートされます。
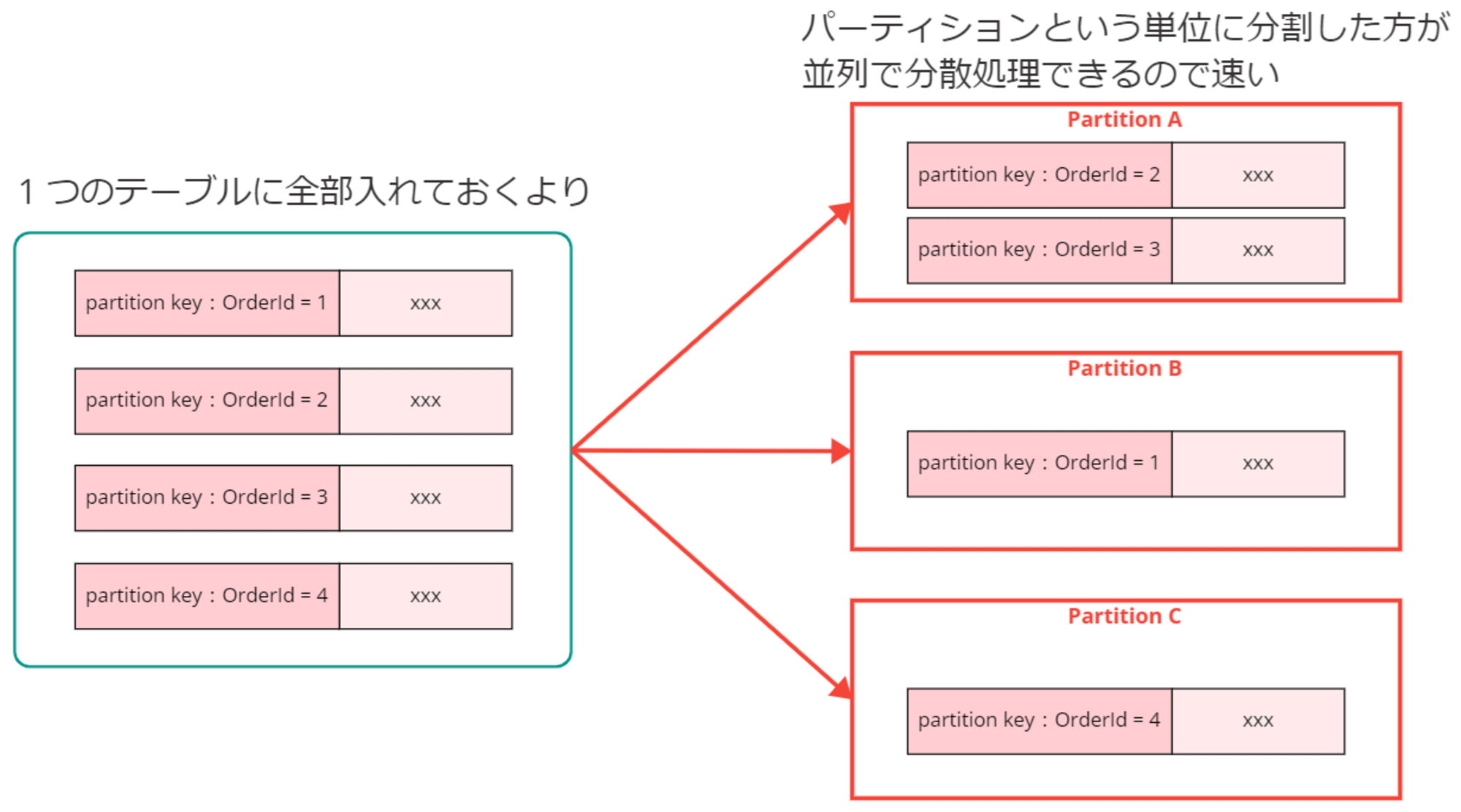
DynamoDB に格納されたアイテムは、パーティションキーによって決められたパーティションに分散して格納されます。
パーティションキーにハッシュ関数をかけたハッシュ値に基づいて、アイテムが格納されるパーティションが決まります。
このため昔はパーティションキーのことをハッシュキーと呼んでいました。
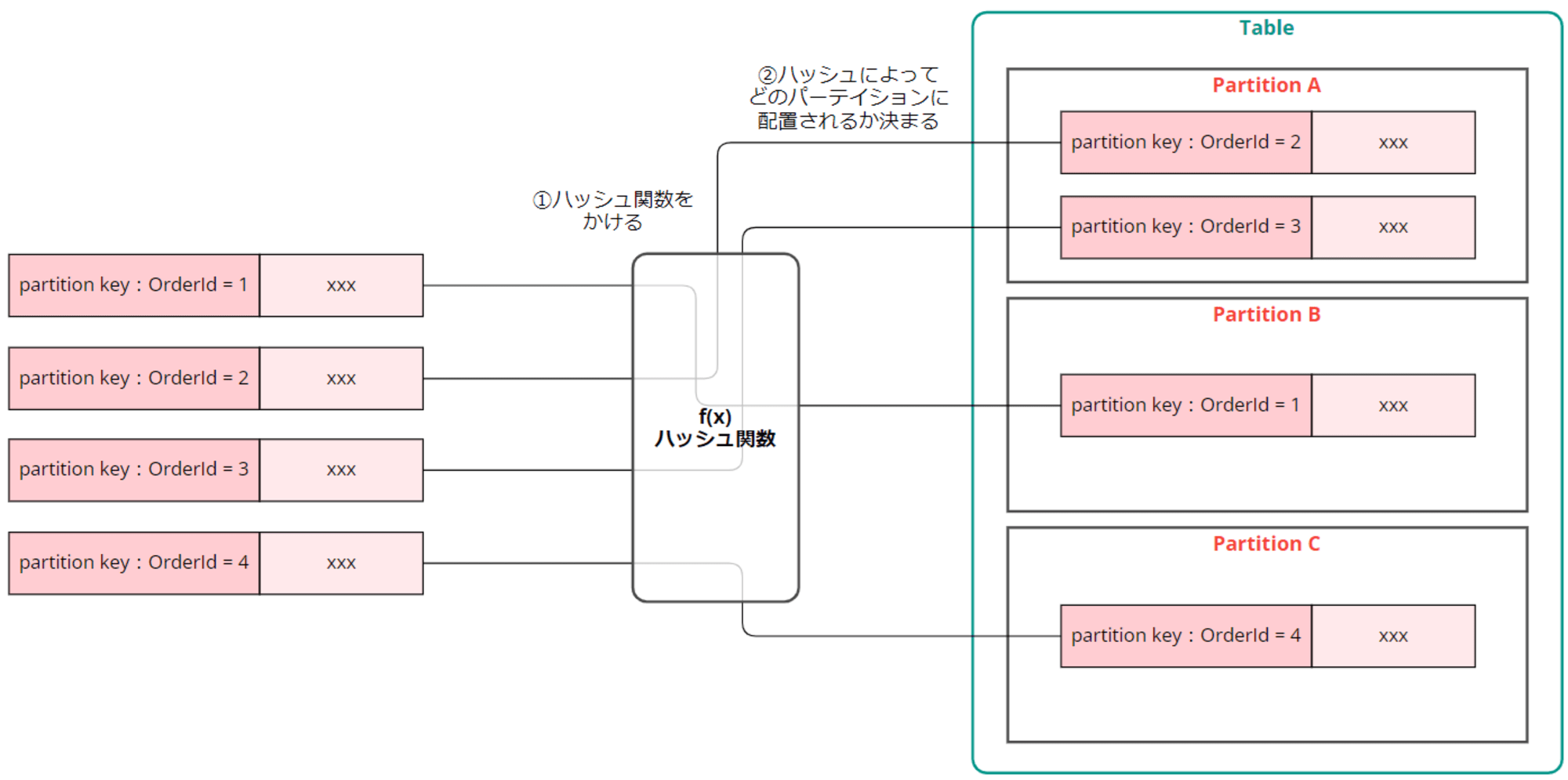
パーティション分割は AWS の内部的に行われるため、ユーザーが指定したり管理することはできません。
つまり、パーティションをユーザーが増やしたり減らしたり、パーティション数を直接指定したりすることはできません。
現在のパーティション数をユーザーが把握することはできませんが、2017 年の古い BlackBelt 資料 PDF 35 ページ以降にパーティション数の計算方法が記載されていますので、机上である程度割り出すことも可能です。
パーティションの計算
パーティション数は以下 2 つの基準を考慮して計算できます。
-
- スループット(読み書きの速度)に基づく計算
-
- データサイズに基づく計算
1. スループット(読み書きの速度)に基づく計算
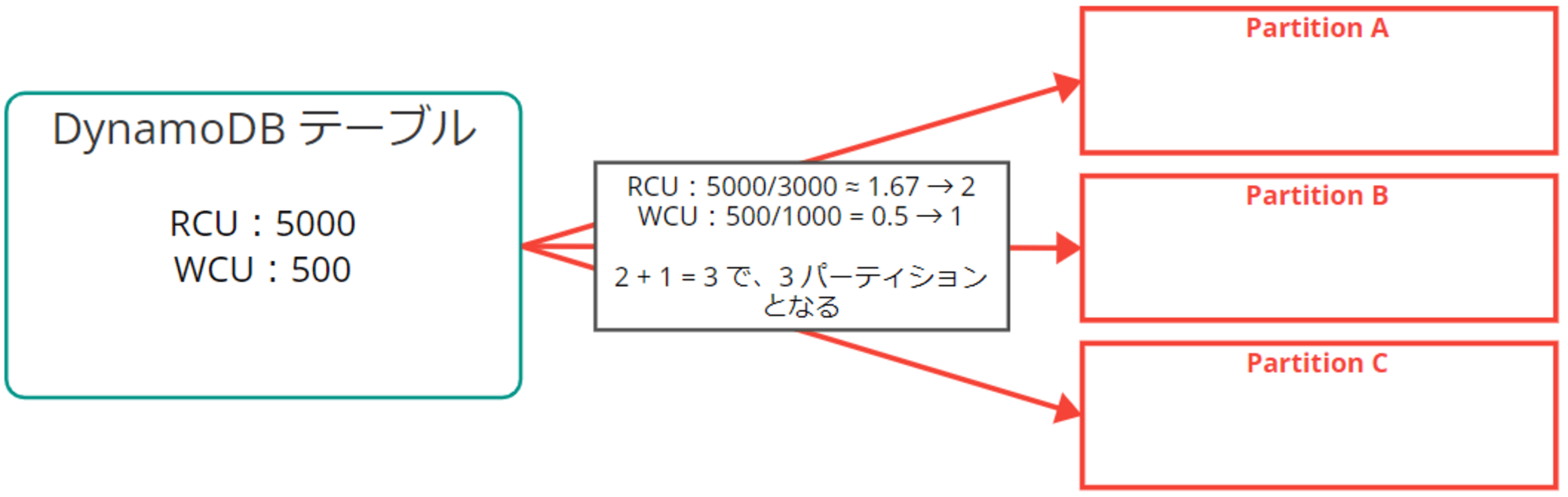
1 つのパーティションが持てる最大キャパシティユニットは以下です。
- 1 つのパーティションが持てる最大 RCU:3000
- 1 つのパーティションが持てる最大 WCU:1000
もし DynamoDB テーブルに設定した RCU、WCU がこれを超えている場合、パーティションは内部で分割され処理が分散されます。
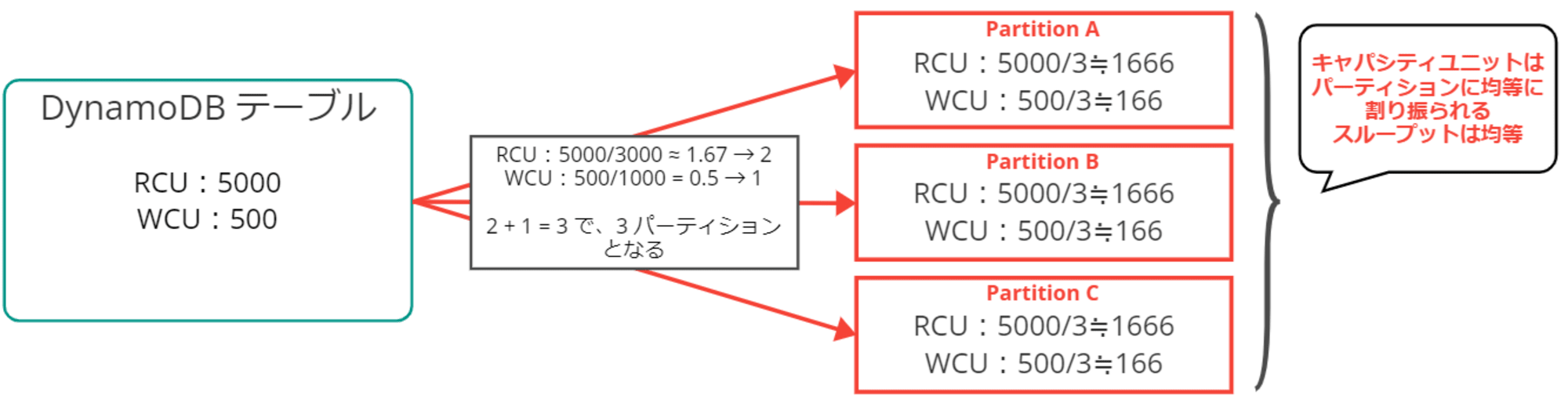
例えば、RCU が 5000、WCU が 500 必要な場合、以下のように計算します。
- RCU:5000/3000 ≈ 1.67 → 2 パーティション
- WCU:500/1000 = 0.5 → 1 パーティション
この場合 2 + 1 = 3 で、3 パーティションになります。
2. データサイズに基づく計算
1 つのパーティションには、最大で 10GB のデータ が保存されます。
DynamoDB テーブル全体のサイズがこの 10GB を超えるたびに、追加のパーティションが必要になります。
例えば、テーブルのサイズが 35GB の場合、35/10 = 3.5 → 4 パーティションが必要です。
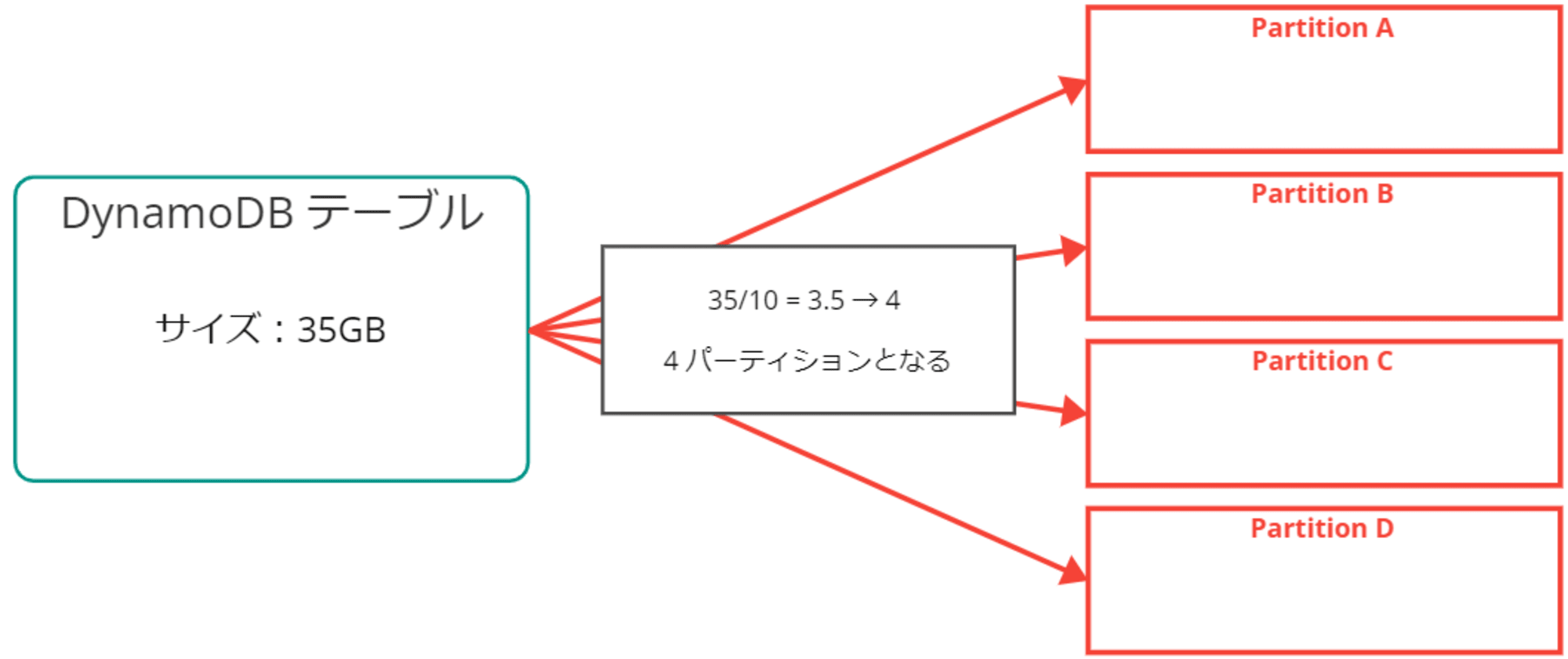
パーティション数の決定
最終的に、「スループットに基づく計算」と「データサイズに基づく計算」それぞれで計算したパーティション数のうち、大きい方の値が実際のパーティション数になります。
例えば、テーブルサイズが 8GB、RCU が 5000、WCU が 500 の場合、以下のように計算します。
- スループットによるパーティション数 = 5000/3000 + 500/1000 ≒ 2.17 → 3 パーティション
- データサイズによるパーティション数 = 8/10 = 0.8 → 1 パーティション
この場合、最終的なパーティション数は多い方で 3 パーティションになります。
パーティショニングについて把握しておかないといけないのはなぜなのか
「へー AWS 側で良しなにやってくれてるんだ。じゃあ別に計算とかしなくてもいいじゃん」
と思いたいところですが、利用者はパーティションの仕組みについてよく把握しておいた方が良い場合があります。
それは本番ワークロードで DynamoDB の性能が落ちたりスロットリングエラーが発生したりしたときです。
特に開発環境ではうまくいっていたのに本番環境で大量のデータを処理しないといけなくなった場合に DynamoDB の性能が落ちるのは、このパーティショニングによる内部的な処理の分散が原因の一端となる場合があるのです。
パーティションの偏りによる性能劣化
テーブルに割り当てられたキャパシティユニットは、パーティションに均等に分散されます。各パーティションのスループットは同じように分散され均等になっているイメージです。
ここでパーティションキーの設計がうまくいっておらず、データへのアクセス(I/O)が一部のパーティションに偏ってしまうことがあります。このようにアクセスが集中してしまうパーティションを「ホットパーティション」と言います。
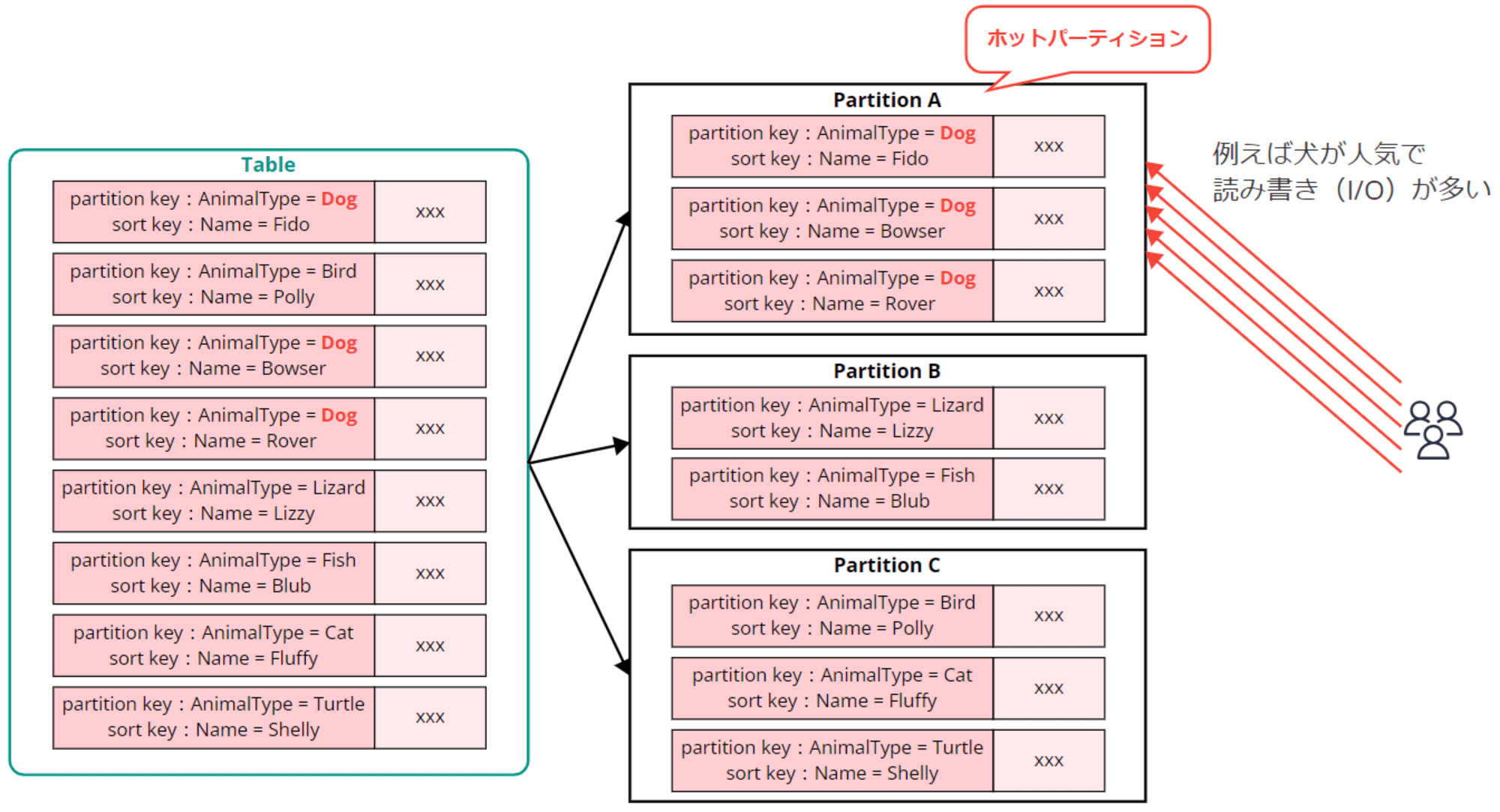
ホットパーティションを防ぐため、データアクセスが均等に分散するようなキー設計が必要です。
データを均等に分散する際に、カーディナリティという概念が用いられることがあります。
カーディナリティ(Cardinality) はデータベースやデータ構造の分野で使用される用語で、特定の集合や列に含まれる 異なる値の数(種類の数) を指します。例えば「都道府県」という列があったとすると、カーディナリティは 47 種類です。
キー設計をする際はカーディナリティも検討し、アクセスが均等に分散されるように検討してください。ドキュメントからキーの例を以下に引用します。
| パーティションキーバリュー | 均一性 |
|---|---|
| ユーザー ID (アプリケーションに多くのユーザーが存在する場合) | 良好 |
| ステータスコード (可能性のあるステータスコードが少しだけある場合) | 不良 |
| 項目の作成日。直近の期間 (日、時、分など) に切り上げられます。 | 不良 |
| デバイス ID (各デバイスが比較的類似した間隔でデータにアクセスする場合)。 | 良好 |
| デバイス ID (追跡中のデバイスが多数あり、そのうちの 1 つのデバイスが他のすべてのデバイスよりも頻繁に使用される場合) | 不良 |
パーティションは増えるが、減らない
以下 BlackBelt の P43 に、一度増えたパーティションは増えるが、減らないという記述があります。
古い資料なのでその後情報が更新されているかもしれませんし、ドキュメントに明確な記載が見つけられなかったのですが、一応どういうことか説明します。
例えば一時的に大きなサイズの大量データを書き込むと、パーティションが増えますね。
その後データを削除しても、パーティションは減らない、ということです。
何が起こるかというと、パーティション数が増えたことにより一つ一つのパーティションに割り当てられたキャパシティユニットが小さく分散され、一つ一つのパーティションのスループットが下がります。
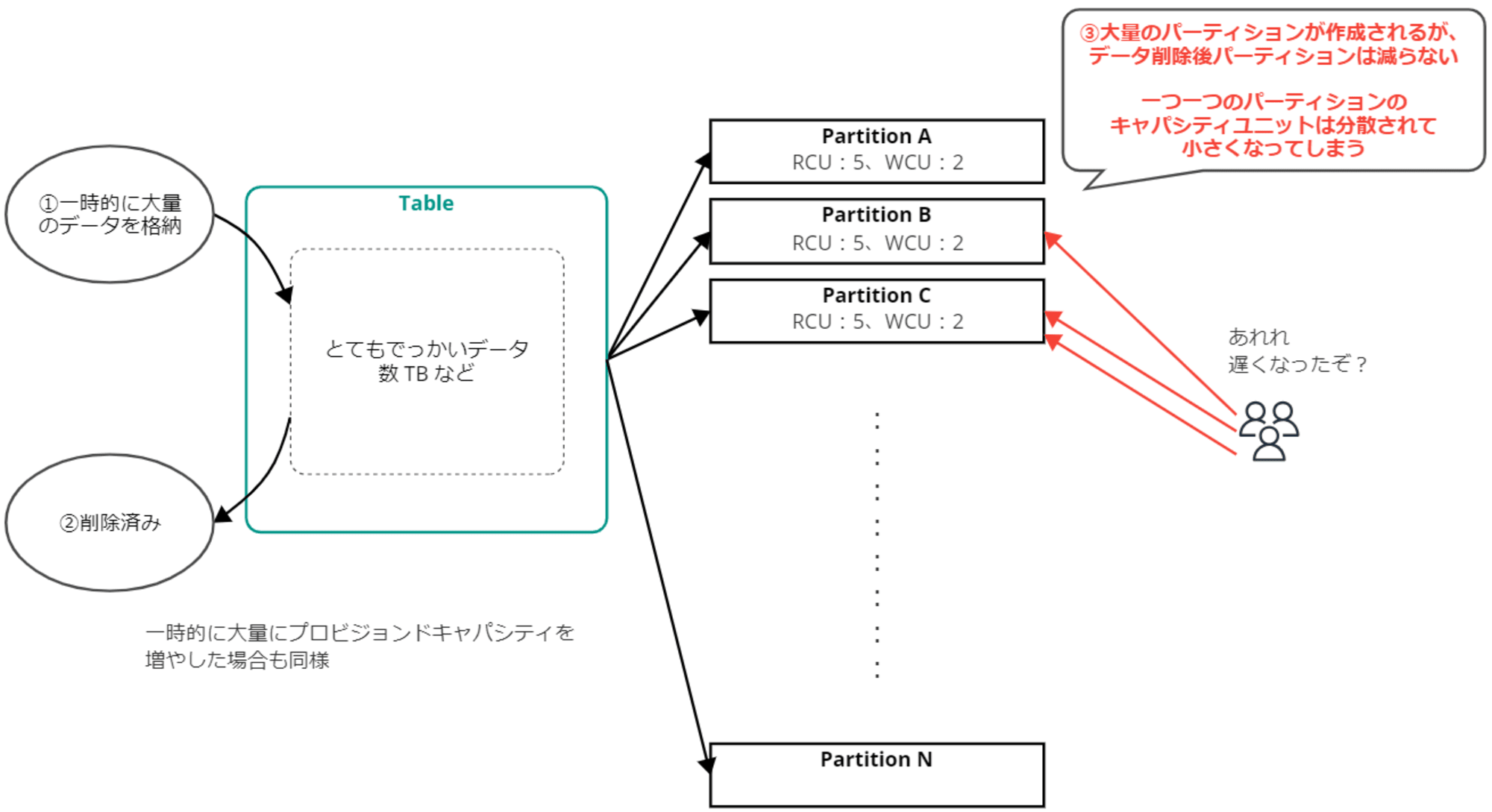
もし負荷試験などで一時的に大量のデータを書き込んで削除したり、プロビジョンドキャパシティを大きく増やしてから減らしたりした際、スループットが落ちたな…と感じることがあれば、これが原因かもしれません。頭の片隅に入れておくと良いです。
この事象はハンズラボ様の記事でも説明されていますのでご参照ください。
(追記)アダプティブキャパシティについて
上記の影響に対して、2019 年にアダプティブキャパシティ機能という機能が追加されています。これは「一部のホットパーティションに、他のパーティションの余った WCU を割り当てることでスロットリングを防ぐ」という機能です。
このアダプティブキャパシティの機能によって、現在ではホットパーティションによる影響が緩和されています。アダプティブキャパシティの機能は DynamoDB テーブルで自動で有効になっており、料金はかかりません。
以下資料でも触れていますので、あわせて参照ください。
一方、基本的なパーティション分割の考え方や、テーブル全体で高いスループットを得るためにカーディナリティが高いキー設計を行っていただくことの重要性は変わりません。
(追記)バーストキャパシティについて
DynamoDB には バーストキャパシティ という仕組みがあり、利用可能なスループットを使い切っていない場合、キャパシティの未使用分を最大 5 分 (300 秒) 蓄えておき、後のスループットのバースト(スパイク)時に消費することで対応します。
つまり、低く設定した WCU や RCU を少し上回るくらいでは、貯蓄された余剰キャパシティを消費することによりスロットリングが発生しません。
以下記事では意図的にスロットリングを発生させていますが、バーストキャパシティを超えさせるため、かなり多めに書き込みを行っています。
DynamoDB の制限
意外と引っかかりがちな制限として、以下があります。
- アイテムの最大サイズは 400 KB
- クエリやスキャンの response サイズは 1MB
終わりに
DynamoDB ではレコードのことをアイテムと呼ぶことも忘れかけていたため、図に整理して思い出せました。
また、パーティショニングについては奥が深く、今回整理できて良かったです。
セカンダリインデックスについても触れたかったのですが、今回はここまでとします。
どなたかの復習に役立てば幸いです。
本記事への質問やご要望については画面下部のお問い合わせ 「DevelopersIO について」 からご連絡ください。記事に関してお問い合わせいただけます。








